近日,吉林大学未来科学国际合作联合实验室人工智能团队在文本相似性及知识图谱补全领域取得了新的进展,两篇论文均被CCF-A类会议WWW 2021接收。WWW,全称为国际万维网大会(The Web Conference) ,是互联网技术领域最重要的国际会议之一,由国际万维网会议委员会(IW3C2)和主办地地方团队合作组织,每年举办一届。
成果1:论文“Using Prior Knowledge to Guide BERT’s Attention in Semantic Textual Matching Tasks”,该成果致力于文本相似性研究,通过探究BERT模型本身拥有哪些知识,分析在BERT模型的哪些位置需要哪些知识。从而进一步将现有的先验知识注入到BERT的多头注意力机制中,在没有额外增加新的训练任务的同时提升模型的效果。实验表明,我们的工作在面对稀疏的训练数据时可以在不牺牲训练成本的同时,提高文本语义相似性任务的分类准确率。论文第一作者为吉林大学硕士研究生夏婷玉,与美国北卡罗莱纳州立大学教堂山分校王悦助理教授以及本校田原助理教授合作完成,通讯作者为吉林大学常毅教授。
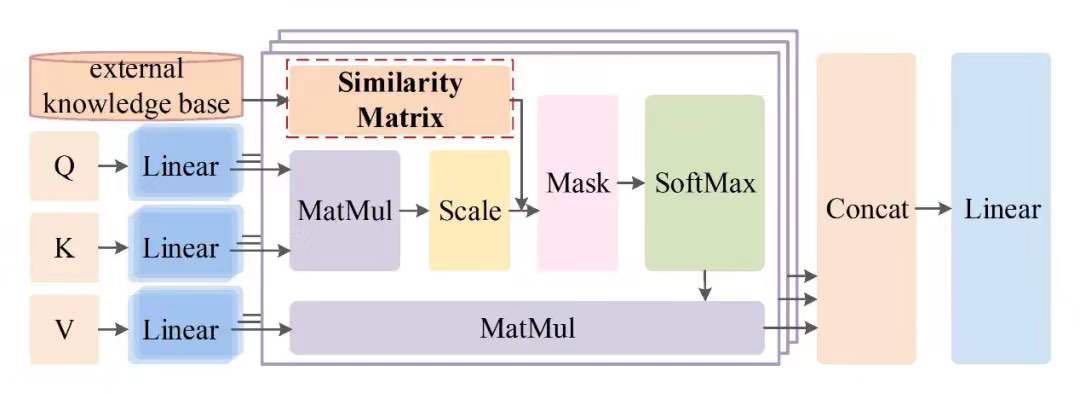
图一:注入先验知识的多头注意力机制框架
成果2:论文“Structure-Augmented Text Representation Learning for Efficient Knowledge Graph Completion”,该成果致力于知识图谱补全领域研究,考虑到现存知识图谱补全方法的弊端,即图嵌入方法泛化能力差以及文本编码方法缺乏结构化知识且计算开销过大的问题,提出一种结构增强的文本表示学习方法,实现了两大类方法的优势互补。具体地,本文基于孪生网络结构,采用预训练语言模型做编码器以充分利用实体和关系的文本信息,并提出两种评分策略以同时建模上下文和结构信息。此外,本文提出了一种自适应集成方案,将两大类方法的得分做出自适应融合,进一步提高了知识图谱补全的性能。实验结果显示,本文所提出的方法能够有效提高知识图谱补全的性能、速度和泛化能力。论文第一作者为吉林大学硕士研究生王博,与悉尼科技大学的Guodong Long教授、Tao Shen博士合作完成,通讯作者为吉林大学常毅教授和王英教授。
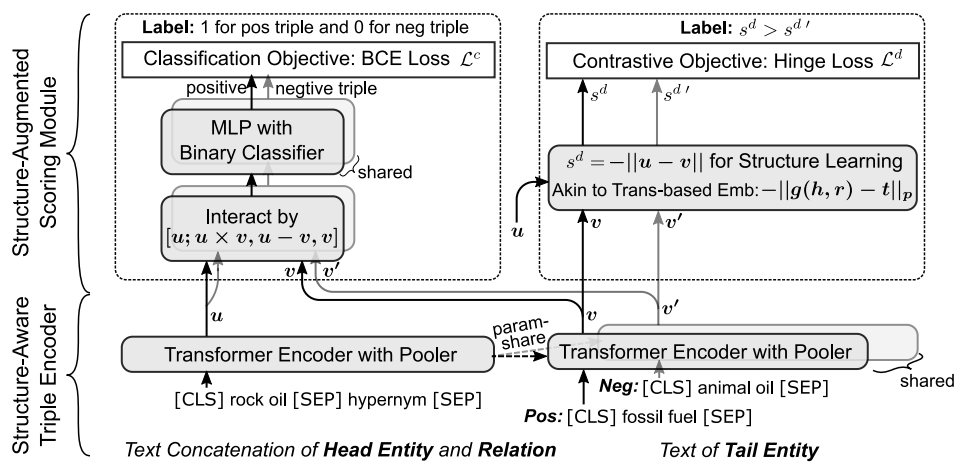
图二:用于知识图谱链接预测的结构增强文本表示模型(StAR)



