近期,吉林大学人工智能学院、未来科学国际合作联合实验室人工智能团队在IEEE Transactions on Knowledge and Data Engineering上发表题为“Sample Efficient Offline-to-Online Reinforcement Learning”的研究工作。该研究提出了一种样本高效的离线转在线强化学习算法,通过乐观探索策略使智能体高效且稳定地探索环境,并通过元适应方法来减小分布偏移,最终在D4RL基准测试上展现了高样本效率(图一)。
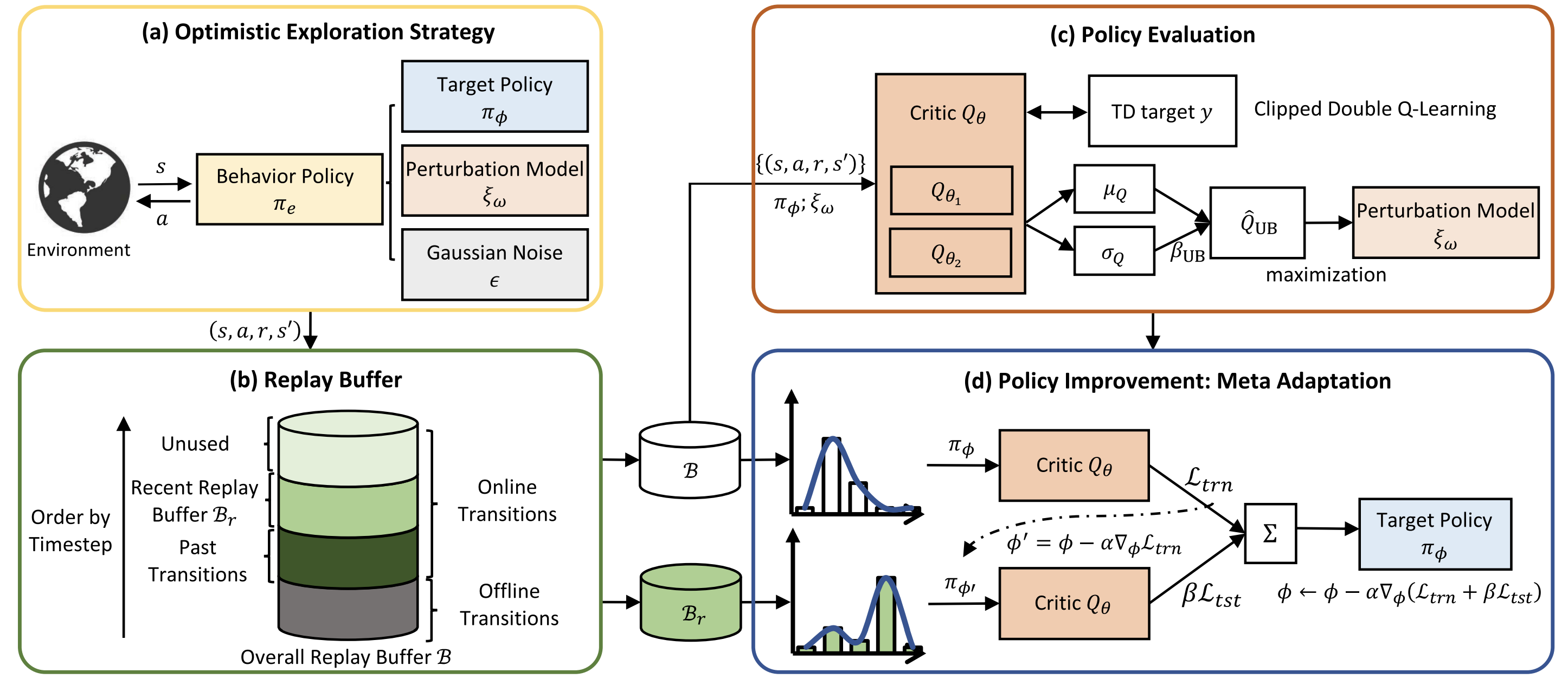
图一:离线转在线强化学习算法框架:(a)乐观探索策略;(b)缓冲回放区;(c)策略评估;(d)基于元适应的策略提升
离线强化学习,即智能体从先前收集的数据集中学习的过程,已被广泛研究并在机器人控制、推荐系统、智慧医疗等领域取得了巨大成功。然而,由于受到离线数据集质量的限制,离线强化学习智能体的性能通常是次优的。因此,在部署之前,通常需要进一步通过在线交互对预训练的离线强化学习智能体进行微调。
尽管预训练-微调范式已经成为现代计算机视觉和自然语言处理中的标准范式。然而,直接借鉴它们的成功经验对于离线转在线强化学习来说并不简单。过往研究表明,简单的在线微调方法不能快速适应在线强化学习环境,甚至可能导致性能下降。这种失败主要归因于分布偏移,即离线数据集和在线回放缓冲区之间的差异。具体来说,由于较差的分布外在线样本的价值估计,在进行采样引导的策略评估时,这种偏差将进一步放大,导致严重的外推误差。因此,策略提升过程无法从在线交互中受益。
该研究提出了一种样本高效的离线转在线强化学习算法,旨在解决两个重要挑战:(1)探索局限性。离线强化学习通常对离线策略评估算法施加严格的限制,以避免采样分布外状态-动作对。由于探索行为策略通常由目标策略派生,这种受限制的预训练策略往往执行保守的动作,使得探索行为策略无法寻找可能产生高奖励并导致长期收益的新颖状态和动作。(2)分布偏移。分布偏移问题使得离线预训练的代理难以快速适应在线微调设置,导致样本效率低下。更糟糕的是,当使用更具探索性的行为策略与环境交互时,这个问题可能会进一步放大。
为此,本研究提出以面对不确定性的乐观原则推导的优化问题,并以迭代方式解决该问题。为了保持行为策略的在线性,实验室人工智能团队将行为策略组成为目标策略和一个扰动模型,以确定探索方向。扰动模型的训练以最大化价值函数的近似上界为目标,该上界模拟了认知不确定性。通过这种方式,可以稳定地得出更具探索性的行为策略,并实现更好的样本效率。此外,本研究提出了一种基于元学习的适应方法,以加速离线和在线数据之间的分布偏移减少。团队采用基于总体回放缓冲区的策略提升。同时,引入一个辅助元目标,以确保用于实现此目标的方向也导致最近回放缓冲区的策略提升。这样可以及时地在策略中传递最近状态的价值估计修正,从而减少分布偏移,加速离线到在线的适应过程。
实验室人工智能团队在D4RL基准测试上进行了大量实验来说明本研究中提出的算法的优越性。实验结果表明,本研究提出的算法在样本效率方面显著优于最先进的离线转在线强化学习算法。
相关的研究成果近期发表在TKDE上,文章第一作者为吉林大学未来科学国际合作联合实验室博士生郭思源,通讯作者为吉林大学陈贺昌教授和常毅教授。该工作得到了国家自然科学基金等项目支持。
全文链接:https://ieeexplore.ieee.org/document/10210487



